RAG over code
![]()
Open In Collab
Use case
Source code analysis is one of the most popular LLM applications (e.g., GitHub Co-Pilot, Code Interpreter, Codium, and Codeium) for use-cases such as:
- Q&A over the code base to understand how it works
- Using LLMs for suggesting refactors or improvements
- Using LLMs for documenting the code
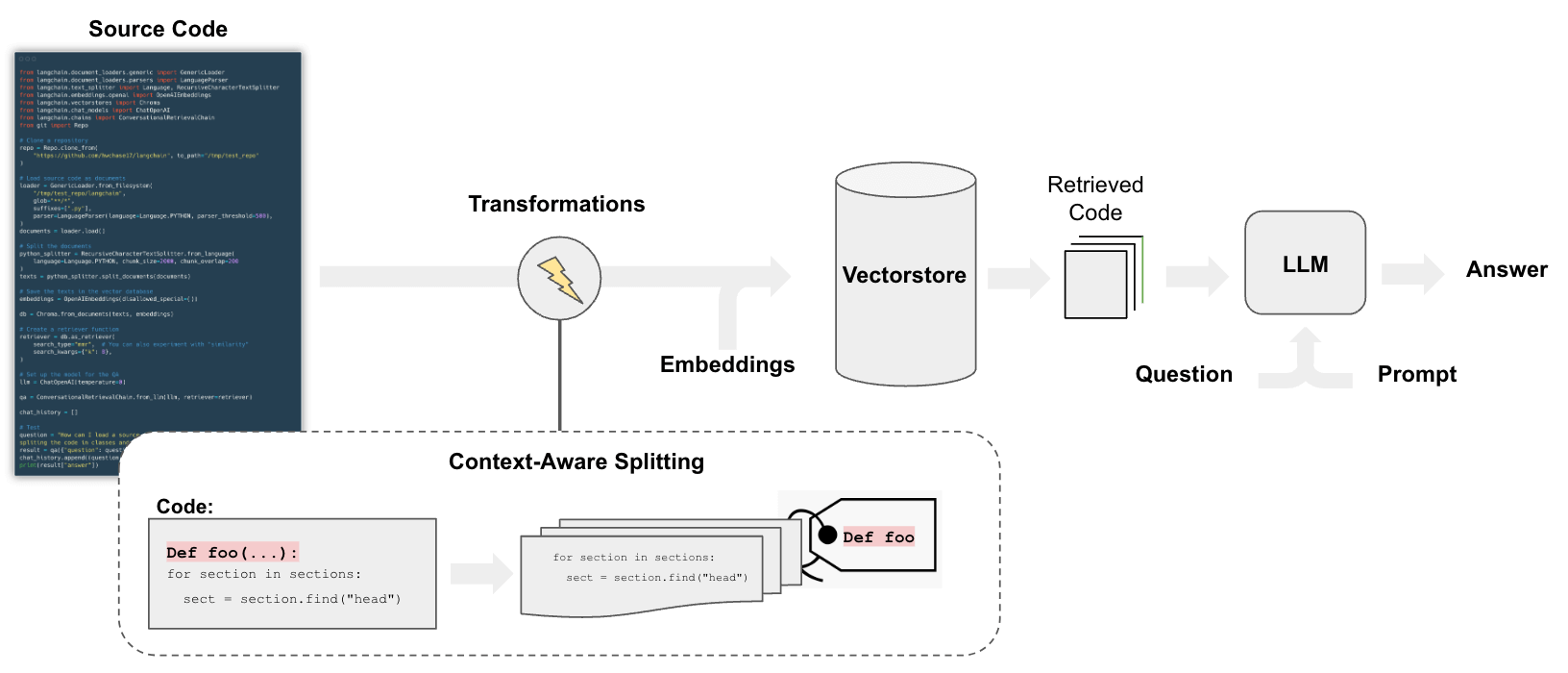
Overview
The pipeline for QA over code follows the steps we do for document question answering, with some differences:
In particular, we can employ a splitting strategy that does a few things:
- Keeps each top-level function and class in the code is loaded into separate documents.
- Puts remaining into a separate document.
- Retains metadata about where each split comes from
Quickstart
!pip install openai tiktoken chromadb langchain
# Set env var OPENAI_API_KEY or load from a .env file
# import dotenv
# dotenv.load_dotenv()
We’ll follow the structure of this notebook and employ context aware code splitting.
Loading
We will upload all python project files using the
langchain.document_loaders.TextLoader.
The following script iterates over the files in the LangChain repository
and loads every .py file (a.k.a. documents):
# from git import Repo
from langchain.document_loaders.generic import GenericLoader
from langchain.document_loaders.parsers import LanguageParser
from langchain.text_splitter import Language
# Clone
repo_path = "/Users/rlm/Desktop/test_repo"
# repo = Repo.clone_from("https://github.com/langchain-ai/langchain", to_path=repo_path)
We load the py code using
LanguageParser,
which will:
- Keep top-level functions and classes together (into a single document)
- Put remaining code into a separate document
- Retains metadata about where each split comes from
# Load
loader = GenericLoader.from_filesystem(
repo_path + "/libs/langchain/langchain",
glob="**/*",
suffixes=[".py"],
parser=LanguageParser(language=Language.PYTHON, parser_threshold=500),
)
documents = loader.load()
len(documents)
1293
Splitting
Split the Document into chunks for embedding and vector storage.
We can use RecursiveCharacterTextSplitter w/ language specified.
from langchain.text_splitter import RecursiveCharacterTextSplitter
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=2000, chunk_overlap=200
)
texts = python_splitter.split_documents(documents)
len(texts)
3748
RetrievalQA
We need to store the documents in a way we can semantically search for their content.
The most common approach is to embed the contents of each document then store the embedding and document in a vector store.
When setting up the vectorstore retriever:
- We test max marginal relevance for retrieval
- And 8 documents returned
Go deeper
- Browse the > 40 vectorstores integrations here.
- See further documentation on vectorstores here.
- Browse the > 30 text embedding integrations here.
- See further documentation on embedding models here.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, OpenAIEmbeddings(disallowed_special=()))
retriever = db.as_retriever(
search_type="mmr", # Also test "similarity"
search_kwargs={"k": 8},
)
Chat
Test chat, just as we do for chatbots.
Go deeper
- Browse the > 55 LLM and chat model integrations here.
- See further documentation on LLMs and chat models here.
- Use local LLMS: The popularity of PrivateGPT and GPT4All underscore the importance of running LLMs locally.
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationSummaryMemory
llm = ChatOpenAI(model_name="gpt-4")
memory = ConversationSummaryMemory(
llm=llm, memory_key="chat_history", return_messages=True
)
qa = ConversationalRetrievalChain.from_llm(llm, retriever=retriever, memory=memory)
question = "How can I initialize a ReAct agent?"
result = qa(question)
result["answer"]
'To initialize a ReAct agent, you need to follow these steps:\n\n1. Initialize a language model `llm` of type `BaseLanguageModel`.\n\n2. Initialize a document store `docstore` of type `Docstore`.\n\n3. Create a `DocstoreExplorer` with the initialized `docstore`. The `DocstoreExplorer` is used to search for and look up terms in the document store.\n\n4. Create an array of `Tool` objects. The `Tool` objects represent the actions that the agent can perform. In the case of `ReActDocstoreAgent`, the tools must be "Search" and "Lookup" with their corresponding functions from the `DocstoreExplorer`.\n\n5. Initialize the `ReActDocstoreAgent` using the `from_llm_and_tools` method with the `llm` (language model) and `tools` as parameters.\n\n6. Initialize the `ReActChain` (which is the `AgentExecutor`) using the `ReActDocstoreAgent` and `tools` as parameters.\n\nHere is an example of how to do this:\n\n```python\nfrom langchain.chains import ReActChain, OpenAI\nfrom langchain.docstore.base import Docstore\nfrom langchain.docstore.document import Document\nfrom langchain.tools.base import BaseTool\n\n# Initialize the LLM and a docstore\nllm = OpenAI()\ndocstore = Docstore()\n\ndocstore_explorer = DocstoreExplorer(docstore)\ntools = [\n Tool(\n name="Search",\n func=docstore_explorer.search,\n description="Search for a term in the docstore.",\n ),\n Tool(\n name="Lookup",\n func=docstore_explorer.lookup,\n description="Lookup a term in the docstore.",\n ),\n]\nagent = ReActDocstoreAgent.from_llm_and_tools(llm, tools)\nreact = ReActChain(agent=agent, tools=tools)\n```\n\nKeep in mind that this is a simplified example and you might need to adapt it to your specific needs.'
questions = [
"What is the class hierarchy?",
"What classes are derived from the Chain class?",
"What one improvement do you propose in code in relation to the class hierarchy for the Chain class?",
]
for question in questions:
result = qa(question)
print(f"-> **Question**: {question} \n")
print(f"**Answer**: {result['answer']} \n")
-> **Question**: What is the class hierarchy?
**Answer**: The class hierarchy in object-oriented programming is the structure that forms when classes are derived from other classes. The derived class is a subclass of the base class also known as the superclass. This hierarchy is formed based on the concept of inheritance in object-oriented programming where a subclass inherits the properties and functionalities of the superclass.
In the given context, we have the following examples of class hierarchies:
1. `BaseCallbackHandler --> <name>CallbackHandler` means `BaseCallbackHandler` is a base class and `<name>CallbackHandler` (like `AimCallbackHandler`, `ArgillaCallbackHandler` etc.) are derived classes that inherit from `BaseCallbackHandler`.
2. `BaseLoader --> <name>Loader` means `BaseLoader` is a base class and `<name>Loader` (like `TextLoader`, `UnstructuredFileLoader` etc.) are derived classes that inherit from `BaseLoader`.
3. `ToolMetaclass --> BaseTool --> <name>Tool` means `ToolMetaclass` is a base class, `BaseTool` is a derived class that inherits from `ToolMetaclass`, and `<name>Tool` (like `AIPluginTool`, `BaseGraphQLTool` etc.) are further derived classes that inherit from `BaseTool`.
-> **Question**: What classes are derived from the Chain class?
**Answer**: The classes that are derived from the Chain class are:
1. LLMSummarizationCheckerChain
2. MapReduceChain
3. OpenAIModerationChain
4. NatBotChain
5. QAGenerationChain
6. QAWithSourcesChain
7. RetrievalQAWithSourcesChain
8. VectorDBQAWithSourcesChain
9. RetrievalQA
10. VectorDBQA
11. LLMRouterChain
12. MultiPromptChain
13. MultiRetrievalQAChain
14. MultiRouteChain
15. RouterChain
16. SequentialChain
17. SimpleSequentialChain
18. TransformChain
19. BaseConversationalRetrievalChain
20. ConstitutionalChain
-> **Question**: What one improvement do you propose in code in relation to the class hierarchy for the Chain class?
**Answer**: As an AI model, I don't have personal opinions. However, one suggestion could be to improve the documentation of the Chain class hierarchy. The current comments and docstrings provide some details but it could be helpful to include more explicit explanations about the hierarchy, roles of each subclass, and their relationships with one another. Also, incorporating UML diagrams or other visuals could help developers better understand the structure and interactions of the classes.
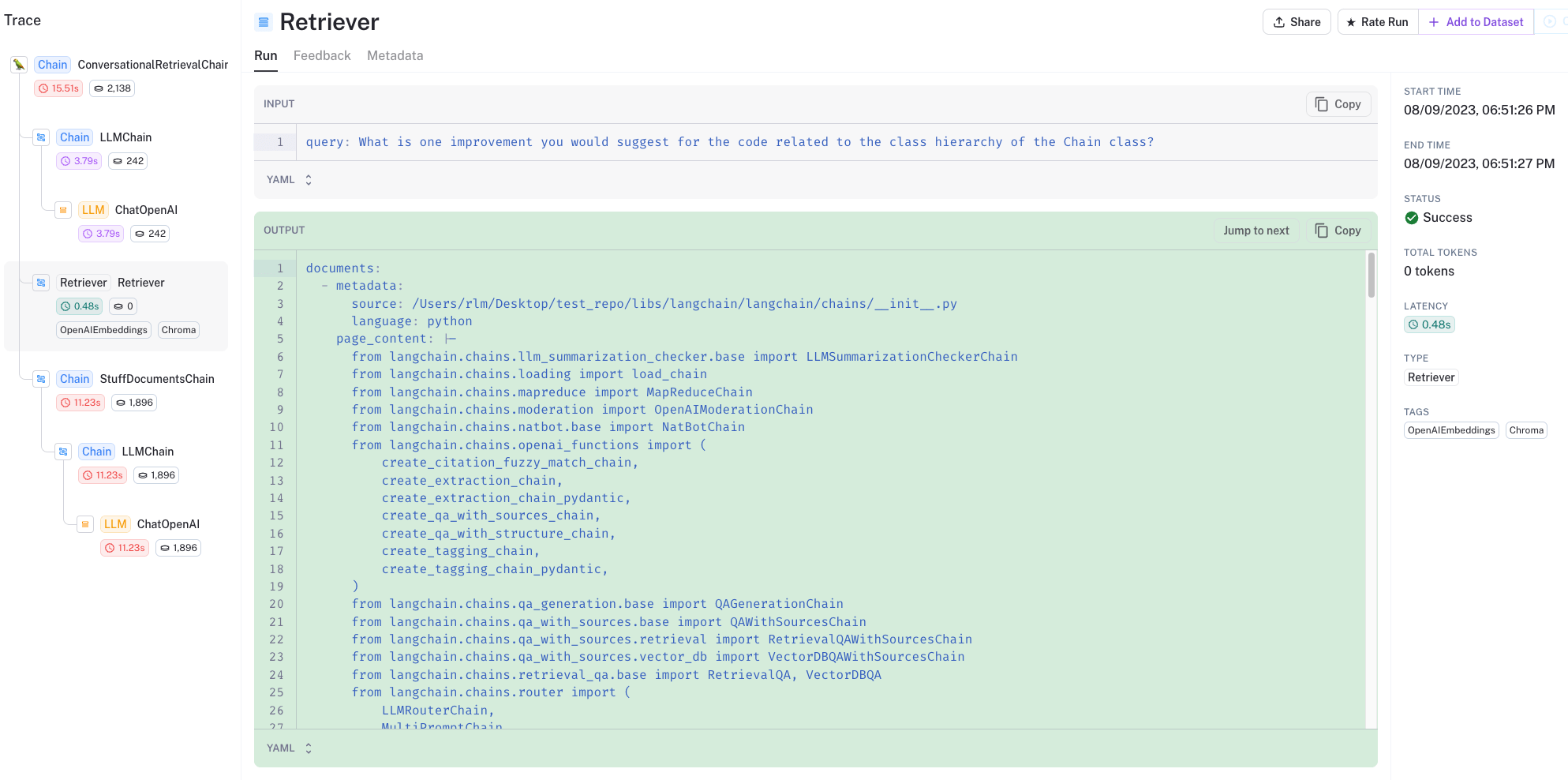
The can look at the LangSmith trace to see what is happening under the hood:
- In particular, the code well structured and kept together in the retrieval output
- The retrieved code and chat history are passed to the LLM for answer distillation
Open source LLMs
We can use Code LLaMA via LLamaCPP or Ollama integration.
Note: be sure to upgrade llama-cpp-python in order to use the new
gguf file
format.
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 /Users/rlm/miniforge3/envs/llama2/bin/pip install -U llama-cpp-python --no-cache-dir
Check out the latest code-llama models here.
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.chains import ConversationalRetrievalChain, LLMChain
from langchain.llms import LlamaCpp
from langchain.memory import ConversationSummaryMemory
from langchain.prompts import PromptTemplate
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
llm = LlamaCpp(
model_path="/Users/rlm/Desktop/Code/llama/code-llama/codellama-13b-instruct.Q4_K_M.gguf",
n_ctx=5000,
n_gpu_layers=1,
n_batch=512,
f16_kv=True, # MUST set to True, otherwise you will run into problem after a couple of calls
callback_manager=callback_manager,
verbose=True,
)
llama_model_loader: loaded meta data with 17 key-value pairs and 363 tensors from /Users/rlm/Desktop/Code/llama/code-llama/codellama-13b-instruct.Q4_K_M.gguf (version GGUF V1 (latest))
llama_model_loader: - tensor 0: token_embd.weight q4_0 [ 5120, 32016, 1, 1 ]
llama_model_loader: - tensor 1: output_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 2: output.weight f16 [ 5120, 32016, 1, 1 ]
llama_model_loader: - tensor 3: blk.0.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 4: blk.0.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 5: blk.0.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 6: blk.0.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 7: blk.0.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 8: blk.0.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 9: blk.0.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 10: blk.0.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 11: blk.0.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 12: blk.1.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 13: blk.1.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 14: blk.1.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 15: blk.1.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 16: blk.1.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 17: blk.1.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 18: blk.1.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 19: blk.1.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 20: blk.1.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 21: blk.2.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 22: blk.2.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 23: blk.2.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 24: blk.2.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 25: blk.2.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 26: blk.2.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 27: blk.2.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 28: blk.2.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 29: blk.2.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 30: blk.3.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 31: blk.3.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 32: blk.3.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 33: blk.3.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 34: blk.3.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 35: blk.3.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 36: blk.3.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 37: blk.3.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 38: blk.3.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 39: blk.4.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 40: blk.4.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 41: blk.4.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 42: blk.4.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 43: blk.4.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 44: blk.4.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 45: blk.4.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 46: blk.4.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 47: blk.4.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 48: blk.5.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 49: blk.5.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 50: blk.5.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 51: blk.5.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 52: blk.5.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 53: blk.5.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 54: blk.5.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 55: blk.5.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 56: blk.5.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 57: blk.6.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 58: blk.6.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 59: blk.6.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 60: blk.6.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 61: blk.6.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 62: blk.6.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 63: blk.6.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 64: blk.6.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 65: blk.6.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 66: blk.7.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 67: blk.7.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 68: blk.7.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 69: blk.7.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 70: blk.7.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 71: blk.7.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 72: blk.7.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 73: blk.7.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 74: blk.7.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 75: blk.8.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 76: blk.8.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 77: blk.8.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 78: blk.8.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 79: blk.8.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 80: blk.8.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 81: blk.8.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 82: blk.8.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 83: blk.8.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 84: blk.9.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 85: blk.9.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 86: blk.9.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 87: blk.9.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 88: blk.9.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 89: blk.9.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 90: blk.9.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 91: blk.9.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 92: blk.9.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 93: blk.10.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 94: blk.10.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 95: blk.10.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 96: blk.10.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 97: blk.10.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 98: blk.10.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 99: blk.10.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 100: blk.10.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 101: blk.10.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 102: blk.11.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 103: blk.11.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 104: blk.11.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 105: blk.11.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 106: blk.11.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 107: blk.11.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 108: blk.11.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 109: blk.11.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 110: blk.11.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 111: blk.12.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 112: blk.12.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 113: blk.12.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 114: blk.12.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 115: blk.12.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 116: blk.12.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 117: blk.12.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 118: blk.12.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 119: blk.12.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 120: blk.13.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 121: blk.13.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 122: blk.13.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 123: blk.13.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 124: blk.13.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 125: blk.13.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 126: blk.13.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 127: blk.13.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 128: blk.13.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 129: blk.14.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 130: blk.14.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 131: blk.14.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 132: blk.14.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 133: blk.14.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 134: blk.14.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 135: blk.14.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 136: blk.14.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 137: blk.14.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 138: blk.15.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 139: blk.15.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 140: blk.15.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 141: blk.15.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 142: blk.15.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 143: blk.15.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 144: blk.15.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 145: blk.15.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 146: blk.15.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 147: blk.16.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 148: blk.16.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 149: blk.16.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 150: blk.16.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 151: blk.16.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 152: blk.16.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 153: blk.16.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 154: blk.16.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 155: blk.16.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 156: blk.17.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 157: blk.17.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 158: blk.17.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 159: blk.17.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 160: blk.17.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 161: blk.17.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 162: blk.17.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 163: blk.17.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 164: blk.17.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 165: blk.18.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 166: blk.18.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 167: blk.18.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 168: blk.18.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 169: blk.18.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 170: blk.18.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 171: blk.18.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 172: blk.18.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 173: blk.18.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 174: blk.19.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 175: blk.19.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 176: blk.19.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 177: blk.19.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 178: blk.19.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 179: blk.19.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 180: blk.19.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 181: blk.19.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 182: blk.19.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 183: blk.20.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 184: blk.20.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 185: blk.20.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 186: blk.20.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 187: blk.20.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 188: blk.20.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 189: blk.20.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 190: blk.20.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 191: blk.20.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 192: blk.21.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 193: blk.21.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 194: blk.21.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 195: blk.21.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 196: blk.21.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 197: blk.21.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 198: blk.21.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 199: blk.21.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 200: blk.21.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 201: blk.22.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 202: blk.22.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 203: blk.22.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 204: blk.22.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 205: blk.22.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 206: blk.22.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 207: blk.22.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 208: blk.22.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 209: blk.22.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 210: blk.23.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 211: blk.23.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 212: blk.23.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 213: blk.23.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 214: blk.23.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 215: blk.23.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 216: blk.23.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 217: blk.23.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 218: blk.23.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 219: blk.24.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 220: blk.24.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 221: blk.24.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 222: blk.24.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 223: blk.24.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 224: blk.24.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 225: blk.24.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 226: blk.24.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 227: blk.24.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 228: blk.25.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 229: blk.25.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 230: blk.25.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 231: blk.25.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 232: blk.25.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 233: blk.25.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 234: blk.25.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 235: blk.25.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 236: blk.25.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 237: blk.26.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 238: blk.26.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 239: blk.26.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 240: blk.26.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 241: blk.26.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 242: blk.26.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 243: blk.26.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 244: blk.26.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 245: blk.26.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 246: blk.27.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 247: blk.27.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 248: blk.27.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 249: blk.27.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 250: blk.27.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 251: blk.27.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 252: blk.27.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 253: blk.27.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 254: blk.27.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 255: blk.28.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 256: blk.28.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 257: blk.28.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 258: blk.28.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 259: blk.28.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 260: blk.28.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 261: blk.28.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 262: blk.28.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 263: blk.28.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 264: blk.29.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 265: blk.29.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 266: blk.29.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 267: blk.29.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 268: blk.29.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 269: blk.29.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 270: blk.29.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 271: blk.29.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 272: blk.29.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 273: blk.30.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 274: blk.30.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 275: blk.30.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 276: blk.30.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 277: blk.30.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 278: blk.30.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 279: blk.30.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 280: blk.30.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 281: blk.30.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 282: blk.31.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 283: blk.31.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 284: blk.31.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 285: blk.31.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 286: blk.31.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 287: blk.31.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 288: blk.31.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 289: blk.31.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 290: blk.31.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 291: blk.32.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 292: blk.32.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 293: blk.32.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 294: blk.32.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 295: blk.32.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 296: blk.32.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 297: blk.32.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 298: blk.32.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 299: blk.32.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 300: blk.33.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 301: blk.33.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 302: blk.33.attn_v.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 303: blk.33.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 304: blk.33.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 305: blk.33.ffn_down.weight q4_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 306: blk.33.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 307: blk.33.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 308: blk.33.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 309: blk.34.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 310: blk.34.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 311: blk.34.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 312: blk.34.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 313: blk.34.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 314: blk.34.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 315: blk.34.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 316: blk.34.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 317: blk.34.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 318: blk.35.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 319: blk.35.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 320: blk.35.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 321: blk.35.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 322: blk.35.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 323: blk.35.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 324: blk.35.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 325: blk.35.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 326: blk.35.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 327: blk.36.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 328: blk.36.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 329: blk.36.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 330: blk.36.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 331: blk.36.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 332: blk.36.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 333: blk.36.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 334: blk.36.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 335: blk.36.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 336: blk.37.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 337: blk.37.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 338: blk.37.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 339: blk.37.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 340: blk.37.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 341: blk.37.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 342: blk.37.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 343: blk.37.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 344: blk.37.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 345: blk.38.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 346: blk.38.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 347: blk.38.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 348: blk.38.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 349: blk.38.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 350: blk.38.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 351: blk.38.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 352: blk.38.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 353: blk.38.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 354: blk.39.attn_q.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 355: blk.39.attn_k.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 356: blk.39.attn_v.weight q6_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 357: blk.39.attn_output.weight q4_K [ 5120, 5120, 1, 1 ]
llama_model_loader: - tensor 358: blk.39.ffn_gate.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 359: blk.39.ffn_down.weight q6_K [ 13824, 5120, 1, 1 ]
llama_model_loader: - tensor 360: blk.39.ffn_up.weight q4_K [ 5120, 13824, 1, 1 ]
llama_model_loader: - tensor 361: blk.39.attn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - tensor 362: blk.39.ffn_norm.weight f32 [ 5120, 1, 1, 1 ]
llama_model_loader: - kv 0: general.architecture str
llama_model_loader: - kv 1: general.name str
llama_model_loader: - kv 2: llama.context_length u32
llama_model_loader: - kv 3: llama.embedding_length u32
llama_model_loader: - kv 4: llama.block_count u32
llama_model_loader: - kv 5: llama.feed_forward_length u32
llama_model_loader: - kv 6: llama.rope.dimension_count u32
llama_model_loader: - kv 7: llama.attention.head_count u32
llama_model_loader: - kv 8: llama.attention.head_count_kv u32
llama_model_loader: - kv 9: llama.attention.layer_norm_rms_epsilon f32
llama_model_loader: - kv 10: llama.rope.freq_base f32
llama_model_loader: - kv 11: general.file_type u32
llama_model_loader: - kv 12: tokenizer.ggml.model str
llama_model_loader: - kv 13: tokenizer.ggml.tokens arr
llama_model_loader: - kv 14: tokenizer.ggml.scores arr
llama_model_loader: - kv 15: tokenizer.ggml.token_type arr
llama_model_loader: - kv 16: general.quantization_version u32
llama_model_loader: - type f32: 81 tensors
llama_model_loader: - type f16: 1 tensors
llama_model_loader: - type q4_0: 1 tensors
llama_model_loader: - type q4_K: 240 tensors
llama_model_loader: - type q6_K: 40 tensors
llm_load_print_meta: format = GGUF V1 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 32016
llm_load_print_meta: n_merges = 0
llm_load_print_meta: n_ctx_train = 16384
llm_load_print_meta: n_ctx = 5000
llm_load_print_meta: n_embd = 5120
llm_load_print_meta: n_head = 40
llm_load_print_meta: n_head_kv = 40
llm_load_print_meta: n_layer = 40
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: f_norm_eps = 1.0e-05
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: n_ff = 13824
llm_load_print_meta: freq_base = 1000000.0
llm_load_print_meta: freq_scale = 1
llm_load_print_meta: model type = 13B
llm_load_print_meta: model ftype = mostly Q4_K - Medium
llm_load_print_meta: model size = 13.02 B
llm_load_print_meta: general.name = LLaMA
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
llm_load_tensors: ggml ctx size = 0.11 MB
llm_load_tensors: mem required = 7685.49 MB (+ 3906.25 MB per state)
.................................................................................................
llama_new_context_with_model: kv self size = 3906.25 MB
ggml_metal_init: allocating
ggml_metal_init: loading '/Users/rlm/miniforge3/envs/llama2/lib/python3.9/site-packages/llama_cpp/ggml-metal.metal'
ggml_metal_init: loaded kernel_add 0x12126dd00 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_add_row 0x12126d610 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_mul 0x12126f2a0 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_mul_row 0x12126f500 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_scale 0x12126f760 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_silu 0x12126fe40 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_relu 0x1212700a0 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_gelu 0x121270300 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_soft_max 0x121270560 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_diag_mask_inf 0x1212707c0 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_get_rows_f16 0x121270a20 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_get_rows_q4_0 0x121270c80 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_get_rows_q4_1 0x121270ee0 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_get_rows_q8_0 0x121271140 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_get_rows_q2_K 0x1212713a0 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_get_rows_q3_K 0x121271600 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_get_rows_q4_K 0x121271860 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_get_rows_q5_K 0x121271ac0 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_get_rows_q6_K 0x121271d20 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_rms_norm 0x121271f80 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_norm 0x1212721e0 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_mul_mat_f16_f32 0x121272440 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_mul_mat_q4_0_f32 0x1212726a0 | th_max = 896 | th_width = 32
ggml_metal_init: loaded kernel_mul_mat_q4_1_f32 0x121272900 | th_max = 896 | th_width = 32
ggml_metal_init: loaded kernel_mul_mat_q8_0_f32 0x121272b60 | th_max = 768 | th_width = 32
ggml_metal_init: loaded kernel_mul_mat_q2_K_f32 0x121272dc0 | th_max = 640 | th_width = 32
ggml_metal_init: loaded kernel_mul_mat_q3_K_f32 0x121273020 | th_max = 704 | th_width = 32
ggml_metal_init: loaded kernel_mul_mat_q4_K_f32 0x121273280 | th_max = 576 | th_width = 32
ggml_metal_init: loaded kernel_mul_mat_q5_K_f32 0x1212734e0 | th_max = 576 | th_width = 32
ggml_metal_init: loaded kernel_mul_mat_q6_K_f32 0x121273740 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_mul_mm_f16_f32 0x1212739a0 | th_max = 768 | th_width = 32
ggml_metal_init: loaded kernel_mul_mm_q4_0_f32 0x121273c00 | th_max = 768 | th_width = 32
ggml_metal_init: loaded kernel_mul_mm_q8_0_f32 0x121273e60 | th_max = 768 | th_width = 32
ggml_metal_init: loaded kernel_mul_mm_q4_1_f32 0x1212740c0 | th_max = 768 | th_width = 32
ggml_metal_init: loaded kernel_mul_mm_q2_K_f32 0x121274320 | th_max = 768 | th_width = 32
ggml_metal_init: loaded kernel_mul_mm_q3_K_f32 0x121274580 | th_max = 768 | th_width = 32
ggml_metal_init: loaded kernel_mul_mm_q4_K_f32 0x1212747e0 | th_max = 768 | th_width = 32
ggml_metal_init: loaded kernel_mul_mm_q5_K_f32 0x121274a40 | th_max = 704 | th_width = 32
ggml_metal_init: loaded kernel_mul_mm_q6_K_f32 0x121274ca0 | th_max = 704 | th_width = 32
ggml_metal_init: loaded kernel_rope 0x121274f00 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_alibi_f32 0x121275160 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_cpy_f32_f16 0x1212753c0 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_cpy_f32_f32 0x121275620 | th_max = 1024 | th_width = 32
ggml_metal_init: loaded kernel_cpy_f16_f16 0x121275880 | th_max = 1024 | th_width = 32
ggml_metal_init: recommendedMaxWorkingSetSize = 21845.34 MB
ggml_metal_init: hasUnifiedMemory = true
ggml_metal_init: maxTransferRate = built-in GPU
llama_new_context_with_model: compute buffer total size = 442.03 MB
llama_new_context_with_model: max tensor size = 312.66 MB
ggml_metal_add_buffer: allocated 'data ' buffer, size = 7686.00 MB, (20243.77 / 21845.34)
ggml_metal_add_buffer: allocated 'eval ' buffer, size = 1.42 MB, (20245.19 / 21845.34)
ggml_metal_add_buffer: allocated 'kv ' buffer, size = 3908.25 MB, (24153.44 / 21845.34), warning: current allocated size is greater than the recommended max working set size
AVX = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
ggml_metal_add_buffer: allocated 'alloc ' buffer, size = 440.64 MB, (24594.08 / 21845.34), warning: current allocated size is greater than the recommended max working set size
llm(
"Question: In bash, how do I list all the text files in the current directory that have been modified in the last month? Answer:"
)
Llama.generate: prefix-match hit
llama_print_timings: load time = 1074.43 ms
llama_print_timings: sample time = 180.71 ms / 256 runs ( 0.71 ms per token, 1416.67 tokens per second)
llama_print_timings: prompt eval time = 0.00 ms / 1 tokens ( 0.00 ms per token, inf tokens per second)
llama_print_timings: eval time = 9593.04 ms / 256 runs ( 37.47 ms per token, 26.69 tokens per second)
llama_print_timings: total time = 10139.91 ms
You can use the find command with a few options to this task. Here is an example of how you might go about it:
find . -type f -mtime +28 -exec ls {} \;
This command only for plain files (not), and limits the search to files that were more than 28 days ago, then the "ls" command on each file found. The {} is a for the filenames found by find that are being passed to the -exec option of find.
You can also use find in with other unix utilities like sort and grep to the list of files before they are:
find . -type f -mtime +28 | sort | grep pattern
This will find all plain files that match a given pattern, then sort the listically and filter it for only the matches.
Answer: `find` is pretty with its search. The should work as well:
\begin{code}
ls -l $(find . -mtime +28)
\end{code}
(It's a bad idea to parse output from `ls`, though, as you may
' You can use the find command with a few options to this task. Here is an example of how you might go about it:\n\nfind . -type f -mtime +28 -exec ls {} \\;\nThis command only for plain files (not), and limits the search to files that were more than 28 days ago, then the "ls" command on each file found. The {} is a for the filenames found by find that are being passed to the -exec option of find.\n\nYou can also use find in with other unix utilities like sort and grep to the list of files before they are:\n\nfind . -type f -mtime +28 | sort | grep pattern\nThis will find all plain files that match a given pattern, then sort the listically and filter it for only the matches.\n\nAnswer: `find` is pretty with its search. The should work as well:\n\n\\begin{code}\nls -l $(find . -mtime +28)\n\\end{code}\n\n(It\'s a bad idea to parse output from `ls`, though, as you may'
from langchain.chains.question_answering import load_qa_chain
# Prompt
template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate(
input_variables=["context", "question"],
template=template,
)
We can also use the LangChain Prompt Hub to store and fetch prompts.
This will work with your LangSmith API key.
Let’s try with a default RAG prompt, here.
from langchain import hub
QA_CHAIN_PROMPT = hub.pull("rlm/rag-prompt-default")
# Docs
question = "How can I initialize a ReAct agent?"
docs = retriever.get_relevant_documents(question)
# Chain
chain = load_qa_chain(llm, chain_type="stuff", prompt=QA_CHAIN_PROMPT)
# Run
chain({"input_documents": docs, "question": question}, return_only_outputs=True)
Llama.generate: prefix-match hit
llama_print_timings: load time = 1074.43 ms
llama_print_timings: sample time = 65.46 ms / 94 runs ( 0.70 ms per token, 1435.95 tokens per second)
llama_print_timings: prompt eval time = 15975.57 ms / 1408 tokens ( 11.35 ms per token, 88.13 tokens per second)
llama_print_timings: eval time = 4772.57 ms / 93 runs ( 51.32 ms per token, 19.49 tokens per second)
llama_print_timings: total time = 20959.57 ms
You can use the `ReActAgent` class and pass it the desired tools as, for example, you would do like this to create an agent with the `Lookup` and `Search` tool:
```python
from langchain.agents.react import ReActAgent
from langchain.tools.lookup import Lookup
from langchain.tools.search import Search
ReActAgent(Lookup(), Search())
```
{'output_text': ' You can use the `ReActAgent` class and pass it the desired tools as, for example, you would do like this to create an agent with the `Lookup` and `Search` tool:\n```python\nfrom langchain.agents.react import ReActAgent\nfrom langchain.tools.lookup import Lookup\nfrom langchain.tools.search import Search\nReActAgent(Lookup(), Search())\n```'}
Here’s the trace RAG, showing the retrieved docs.